Project Generative AI Image Lexicon: Exploring the latent space of generative images by building a visual dictionary of the “hidden vocabulary” of text-to-image models.
In an effort to better understand the latent space of generative models, I started a project to create a visual lexicon or dictionary of AI-generated images corresponding to gibberish prompts. The goal of this project is to visualize the related prompts and images on an embedding plot, which would enable us to conceptualize the latent space of these models as a reduced-dimensional representation. The visual lexicon will catalog gibberish prompts that result in vivid generative images, and help us interpret the patterns, connections, similarities, differences and anomalies that emerge from the mapping.
Collaborators: Flora Weil and Alex Taylor (leveraging their tool 'Nephila' as the UI to showcase the findings)
Research Exploration, March 2024 (ongoing)
Background
Generative models are capable of producing realistic and diverse images from natural language prompts. However, not all prompts are equally meaningful or interpretable by humans. Some prompts, especially those that seem like gibberish or nonsensical, may result in surprising, rich, vivid and coherent images that are not related to the conventional meanings of the words or phrases. A recent paper by Daras (2022) uncovered that images produced from seemingly random phrases could reveal the “hidden vocabulary” of these generative models.

“It was not clear to us if some of the gibberish words are misspellings of normal words in different languages, but we could not find any such examples in our search.” This suggests that there is a complex, nonlinear relationship between text and image generation that is not fully understood by humans or the model itself.


Images I generated using text-to-image models from gibberish prompts
Based on my explorations here, some interesting findings were:
ChatGPT has advanced content filtering which sometimes prohibits generating outputs for gibberish prompts. However, sometimes it generates images “inspired by” the imagined nonsensical phrases, which is not the same as an established connection between the term and image.
I was able to generate outputs in Microsoft Designer and Copilot for certain prompts when other models like Gemini or ChatGPT wouldn’t. Also, certain previous prompts from the DALLE 2 paper no longer work for DALLE 3, or other models like Microsoft Copilot. This might also indicate that different models and different versions of models have different latent spaces.
Keyboard smash doesn’t seem to generate meaningful outputs. Models might only create vivid images when the gibberish from text originally generated in the model produced image.
Submitting prompts in different human languages can lead to different results, indicating that cultural nuances are encoded in images produced via non-English language prompts. For example, Hindi inputs produce images loaded with Hindu religious imagery in Copilot but not in ChatGPT.
Goal
The aim of this project is to create a visual lexicon of AI-generated images corresponding to text input prompts. The visual lexicon will catalog gibberish prompts that result in vivid generative images, and explore the patterns, similarities, differences and anomalies that emerge from the mapping. The visual lexicon will also serve as a tool for interpreting and navigating the latent space of the generative model, where the dimensions and boundaries of text and image generation are revealed and challenged. We can leverage Nephila as the user interface for the visual lexicon, so users can browse, search, upload, filter and interact with the prompts and images.

Image from Nephila graph (embedding plot)

Image generated by ChatGPT “latent space of text-to-image models”
Expected Outcomes
The expected outcomes of this project are:
A visual lexicon or a dictionary of AI-generated images corresponding to gibberish prompts from an LLM, that showcases the hidden vocabulary and latent space of the generative model.
We could expand to include gibberish prompts with no output so those get ruled out but are still documented.
A better understanding of the relationship between text and image generation, and the factors and mechanisms that influence the mapping.
We could expand to include non-gibberish prompt entries. That way we can start to see patterns and map gibberish to legible phrases.
A new way of exploring and interpreting the generative capabilities and limitations of different models, and the potential applications and implications of the technology.
A novel and engaging experience for users, who can discover, create and interact with the visual lexicon.
Method
The method for creating the visual lexicon will consist of the following steps:
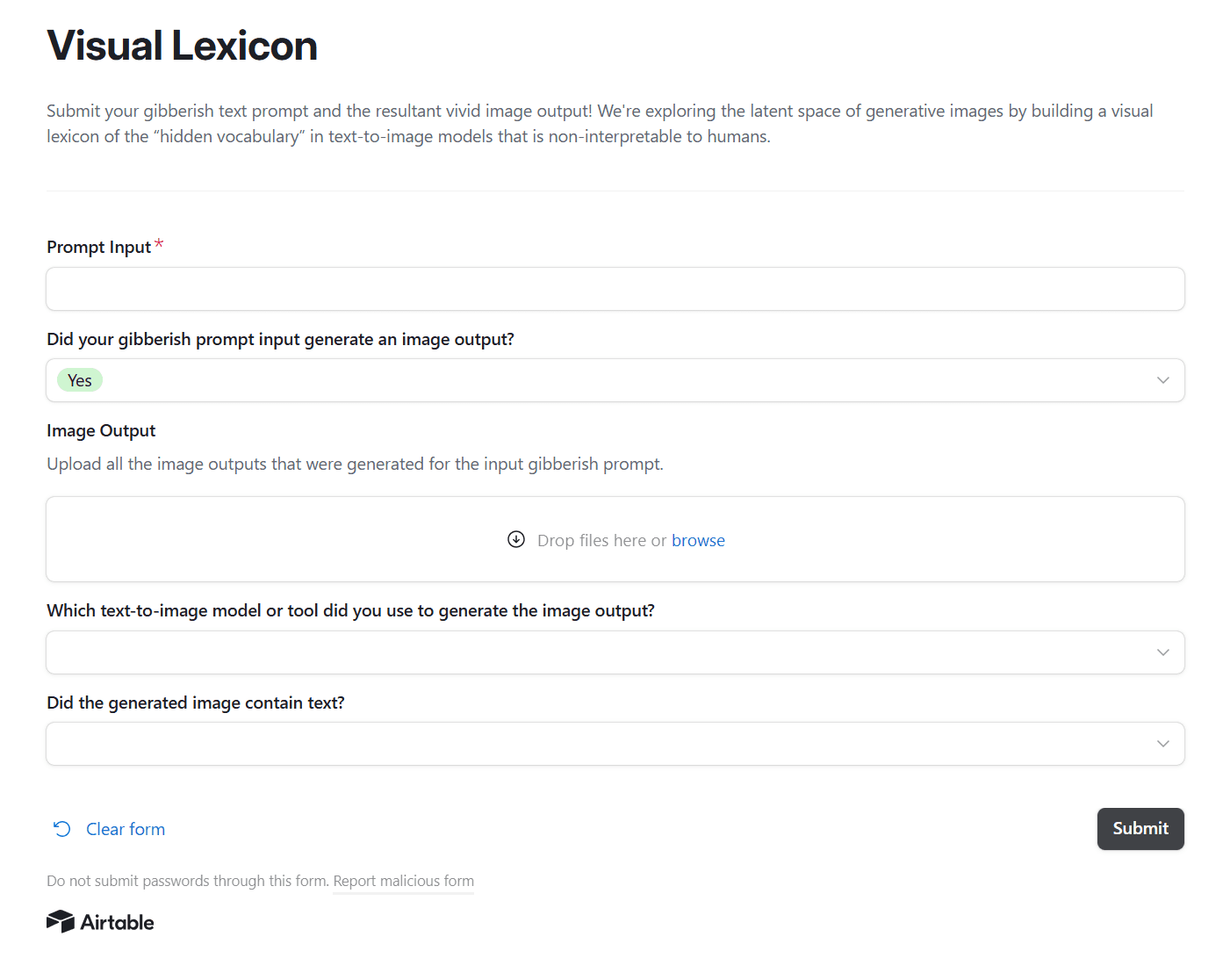
Airtable upload a text prompt, image and model
To make the connections between images through keywords, we need OpenAI API access.
First step is doing the connections manually (embeddings or keyword)
Nephila fe-ed-esque – Automatically updates the knowledge graph
Search through the graph
Text field to enter gibberish prompt
Browser extension fe-ed integration
Schema
Database schema for the graph, comprised of fields inputted by the user as well as metadata and generated fields:
User submitted inputs
Image
Input prompt
Generative AI model or tool used to generate (e.g. ChatGPT, Microsoft Copilot, Midjourney, Gemini)
This will help determine which latent space that entry belongs in,
similar to these category filters
Metadata collected at submission
Date submitted
UserID
Post-processing
Keywords/image description or high-level concepts
This will help us group together or match related images so that we can eventually find commonalities between images and map them in their respective space with corresponding connections.
Image-to-text to extract keywords
Explore OpenAI embeddings/ run t-SNE